1. Introduction
Goldwasser, Micali and Rackoff [GMR89] introduced zero-knowledge proofs that enable a prover to convince a verifier that a statement is true without revealing anything else. They have three core properties:
- Completeness: Given a statement and a witness, the prover can convince the verifier.
- Soundness: A malicious prover cannot convince the verifier of a false statement.
- Zero-knowledge: The proof does not reveal anything but the truth of the statement
1.1. Contribution
Succinct NIZK We construct a NIZK argument for arithmetic circuit satisfiability where a proof consists of only 3 group elements. In addition to being small, the proof is also easy to verify. The verifier just needs to compute a number of exponentiations proportional to the statement size and check a single pairing product equation, which only has 3 pairings.
2. Preliminaries
2.1 Bilinear Groups
We will work over bilinear groups \((p, \mathbb{G_{1}}, \mathbb{G_{2}}, \mathbb{G_{T}} , e, g, h)\) with the following properties:
- \(\mathbb{G_{1}}, \mathbb{G_{2}}, \mathbb{G_{T}} \)are groups of prime order \(p\)
- The pairing \( e:\mathbb{G_{1}} \times \mathbb{G_{2}} \rightarrow \mathbb{G_{T}}\) is a bilinear map
- \(g\) is a generator for \(\mathbb{G_{1}}\), \(h\) is a generator for \(\mathbb{G_{2}}\), and \(e(g,h)\) is a generator for \(\mathbb{G_{T}}\)
There are many ways to set up bilinear groups both as symmetric bilinear groups where \(\mathbb{G_{1}} = \mathbb{G_{1}}\) and as asymmetric bilinear groups where \(\mathbb{G_{1}} \neq \mathbb{G_{1}}\). Galbraith, Paterson and Smart [GPS08] classify bilinear groups as Type I where \(\mathbb{G_{1}} = \mathbb{G_{2}}\), Type II where there is an efficiently computable non-trivial homomorphism \(\Phi : \mathbb{G_{2}} \rightarrow \mathbb{G_{1}}\), and Type III where no such efficiently computable homomorphism exists in either direction between \(\mathbb{G_{1}}\) and \(\mathbb{G_{2}}\). Type III bilinear groups are the most efficient type of bilinear groups and hence the most relevant for practical applications.
As a notation for group elements, we write \( \lbrack a \rbrack_{1} \) for \( g^a\), \( \lbrack b \rbrack_{2}\) for \( h^b\) and \( \lbrack c \rbrack_{T}\) for \(e(g,h)^{c} \). A vector of group elements will be represented as \( \lbrack \mathbf{a} \rbrack_{i} \). Given two vectors of \(n\) group elements \( \lbrack \mathbf{a} \rbrack_{1} \) and \( \lbrack \mathbf{b} \rbrack_{2} \), we define their dot product as \( \lbrack \mathbf{a} \rbrack_{1} \cdot \lbrack \mathbf{b} \rbrack_{2} = \lbrack \mathbf{a} \cdot \mathbf{b} \rbrack_{T} \), which can be efficiently computed using the pairing \(e\).
Protocol
R1CS
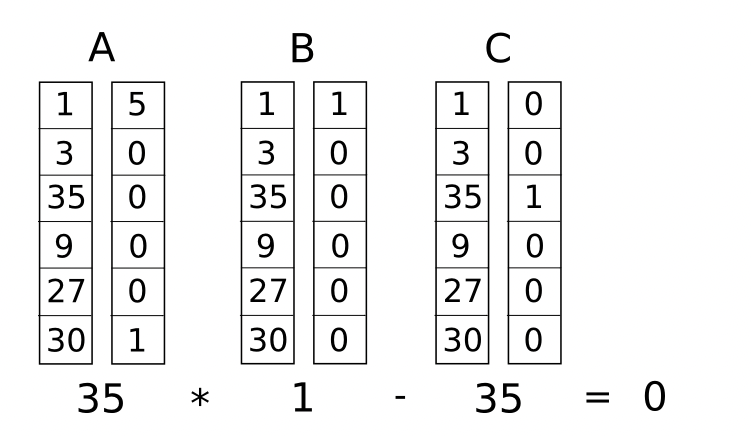
Let \(A, B,C\) be \(m \times n\) matrices with entries from field \( \mathbb{F}\). An R1CA instance takes the form:
\[ \tag{1} (z\cdot A) \odot (z \cdot B) = z \cdot C \]
where \(\cdot\) denotes dot product and \(\odot\) denotes entry-wise product. we required \(z_0 = 1\) because otherwise, \(z=0\) would satisfy every R1CS instance.
note: m is the number of witness, n is number of constraints.
QAP
Consider an arithmetic circuit \({C, x,y}\) with addition and multiplication gates, where we designate some input/output wires to specify statement \(x\) and the rest of the wires to specify witness \(\omega\). The prover wants to convince the verifier that there exists a witness \(\omega\) such that \(C(x,\omega) = y\). If the prover knows a witness \(\omega\), then they know a vector \(z\) that satisfies the constraint of the R1CS. We set the solution vector \(z\) to be an \(m\)-length vector, where \(z_0=1\). each remaining entry of \(z\) represents either the statement \(x\) or witness \(\omega\). Namely, \(x=\{z_1, …, z_l\}\) and \(\omega=\{ z_{l+1},…,z_{m}\}\).
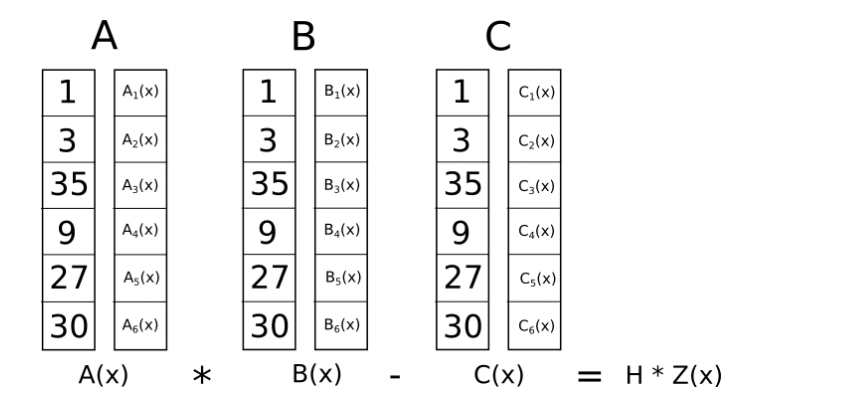
Choose arbitrary distinct elements \(\{r_1, r_2, …, r_n\} \in \mathbb{F}\), where \(r_i\) indicating gate number. We define polynomial coefficient matrices such that each polynomial evaluation encodes an R1CS constraint:
\[\tag{2} A_i(r_q) = A_{i,q} \quad B_i(r_q) = B_{i,q} \quad C_i(r_q) = C_{i,q} \]
where \(i = 1,…,m; q=1,…,n\)
we sum these polynomial vector groups to define three univariate polynomials
\[ \tag{3} A(X) = \sum_{i=0}^{m}z_iA_i(X) \quad B(X) = \sum_{i=0}^{m}z_iB_i(X) \quad C(X) = \sum_{i=0}^{m}z_iC_i(X)\]
The witness vector \(z\), where \(z_0=1\), will satisfy the \(n\) equations in the R1CS instance if and only if at each point \(\{r_1, r_2,…r_n\}\):
\[ \tag{4} \sum_{i=0}^{m}z_iA_i(r_q) \cdot \sum_{i=0}^{m}z_iB_i(r_q) = \sum_{i=0}^{m}z_iC_i(r_q)\]
We know \(t(x):=(x-r_1)(x-r_2)…(x-r_n) =\prod_{q=1}^{n}(x-r_q)\) is the lowest degree monomial such that \(t(r_q)=0\) in each point. Thus, we can reformulate the above as:
\[ \tag{5} \sum_{i=0}^{m}z_iA_i(r_q) \cdot \sum_{i=0}^{m}z_iB_i(r_q) = \sum_{i=0}^{m}z_iC_i(r_q) \mod t(X)\]
Thus, the derived QAP defines the following relation R, where \(z_0 =1\)
\(
\begin{equation}
R =
\begin{cases}
x=(z_1,…,z_l) \in \mathbb{F}^l \\
\omega =(z_{l+1},…,z_m) \in \mathbb{F}^{m-l} \\
\sum_{i=0}^{m}z_iA_i(r_q) \cdot \sum_{i=0}^{m}z_iB_i(r_q) = \sum_{i=0}^{m}z_iC_i(r_q) \mod t(X)
\end{cases}
\end{equation}
\)
Verifying the QAP
Let these QAP polynomials be defined as \(A(X), B(X), C(X)\) where \(A(X) = \sum_{i=0}^{m}z_iA_i(X)\) and similarly for \(B,C\). Let \(g_z\) denote the d-degree polynomial, where \(d\le 2(n-1)\) since \(A(X), B(X), C(X)\) are at most degree \(n-1\)
\[ g_z(X) = \sum_{i=0}^{m}z_iA_i(X) \cdot \sum_{i=0}^{m} z_iB_i(X) - \sum_{i=0}^{m}z_iC_i(X) \]
To verify the QAP, we show the existence of a low-degree polynomial \( h(X) = \frac{g_z(X)}{t(X)} \)
Non-Interactive Zero-Knowledge(NIZK) arguments for QAP
Consider \(R=(p, \mathbb{G_1}, \mathbb{G_2}, \mathbb{G_T}, e, g_1, g_2, l, \{A_i(X), B_i(X), C_i(X)\}, t(X))\)
Recall \(x=(z_1,…,z_l) \in \mathbb{Z}_{p}^{l}\)
and \(\omega=(z_{l+1},…,z_m) \in \mathbb{Z}_{p}^{m-l}\), where \(z_0=1\). The relation defines
\[ A(X) \cdot B(X) -C(X) = h(X)t(X) \]
Trusted Setup
Groth16 uses a two-step trusted setup to generate the common reference string (CRS). The trusted setup consists of two phases: the first is generic and the second is specific to the circuit.
As our CRS, we generate the random field elements \(\alpha, \beta, \gamma, \delta, \tau \in \mathbb{Z}_{p}^{*}\)
phase 1 powers of tau
\( (\lbrack \tau^0 \rbrack_{1}, \lbrack \tau^1 \rbrack_{1}, \lbrack \tau^2 \rbrack_{1},…, \lbrack \tau^{2(n-1)} \rbrack_{1}) \)
\( (\lbrack \tau^0 \rbrack_{2}, \lbrack \tau^1 \rbrack_{2}, \lbrack \tau^2 \rbrack_{2},…, \lbrack \tau^{n-1} \rbrack_{2}) \)
\( \lbrack \alpha \rbrack_{1} \cdot (\lbrack \tau^0 \rbrack_{1}, \lbrack \tau^1 \rbrack_{1}, \lbrack \tau^2 \rbrack_{1},…, \lbrack \tau^{n-1} \rbrack_{1}) \)
\( \lbrack \beta \rbrack_{1} \cdot (\lbrack \tau^0 \rbrack_{1}, \lbrack \tau^1 \rbrack_{1}, \lbrack \tau^2 \rbrack_{1},…, \lbrack \tau^{n-1} \rbrack_{1}) \)
\(\lbrack \beta \rbrack_{2}\)
phase 2
Given \(A_i, B_i, C_i\), we define polynomials \(L_i: L_i(X) = \beta \cdot A_i(X) + \alpha \cdot B_i(X) +C_i(X) \). We cannot compute \(L_i(X)\) directly because \(\alpha\) and \(\beta\) are private, so instead, we construct \(L_i(\tau)\cdot g_i\) using values computed in Phase 1.
providng key (pk)
\((\lbrack \alpha \rbrack_{1}, \lbrack \beta \rbrack_{1}, \lbrack \delta \rbrack_{1})\)
\((\lbrack \tau^0 \rbrack_{1}, \lbrack \tau^2 \rbrack_{1}, \lbrack \tau^2 \rbrack_{1},…, \lbrack \tau^{n-1} \rbrack_{1})\)
\( \lbrack \delta^{-1} \rbrack_{1} \cdot( \lbrack L_l(\tau) \rbrack_{1}, \lbrack L_{l+1}(\tau) \rbrack_{1}, …, \lbrack L_{n-1}(\tau) \rbrack_{1} ) \)
\( \lbrack \delta^{-1} \rbrack_{1} \cdot (\lbrack \tau^0 \rbrack_{1}, \lbrack \tau^1 \rbrack_{1},\lbrack \tau^2 \rbrack_{1},…, \lbrack \tau^{n-1} \rbrack_{1}) \cdot \lbrack t(\tau) \rbrack_{1} \)
\( \lbrack \beta \rbrack_{2}, \lbrack \delta \rbrack_{2}\)
\((\lbrack \tau^0 \rbrack_{2}, \lbrack \tau^1 \rbrack_{2}, \lbrack \tau^2 \rbrack_{2},…, \lbrack \tau^{n-1} \rbrack_{2})\)
Verification key (vk)
\(\lbrack \alpha \rbrack_{1}\)
\( \lbrack \gamma^{-1} \rbrack_{1} \cdot( \lbrack L_0(\tau) \rbrack_{1}, \lbrack L_{1}(\tau) \rbrack_{1},\lbrack L_{2}(\tau) \rbrack_{1}, …, \lbrack L_{l-1}(\tau) \rbrack_{1} ) \)
\( (\lbrack \beta \rbrack_{2}, \lbrack \gamma \rbrack_{2}, \lbrack \delta \rbrack_{2}) \)
Formal Groth16 NIZK argument
- \((pk,vk) \leftarrow SETUP(R)\): Choose \(vk=(\alpha,\beta,\gamma,\delta,\tau) \in \mathbb{Z}_p^{*}\) and compute proving key
\(\left(\left[p k_1\right]_1,\left[p k_2\right]_2\right)\)
\[
pk_1=(\alpha,\beta,\delta,
\{ \tau^i \}_{i=0}^{n-1},
\left\{ \frac{\beta A_i(\tau) + \alpha B_i(\tau) + C_i(\tau)}{\gamma} \right\}_{i=0}^{l},
\left\{ \frac{\beta A_i(\tau) + \alpha B_i(\tau) + C_i(\tau)}{\delta} \right\}_{i=l+1}^{m},
\{ \frac{\tau^i \cdot t(\tau) }{\delta}\}_{i=0}^{n-2}
)\]
\[ pk_2=(\beta,\delta,\gamma, \{ \tau^i \}_{i=0}^{n-1}) \]
- \(\pi \leftarrow PROVE(R, pk, x,\omega)\): Given witness \(\omega=(z_{l+1},…,z_m)\) and two random \((r,s)\in \mathbb{Z}_p\), compute \(\pi=(\lbrack A \rbrack_{1}, \lbrack C \rbrack_{1}, \lbrack B \rbrack_{2})\) where
\[ A= \alpha +\sum_{i=0}^{m}z_iA_i(\tau)+r\delta\]
\[ B= \beta +\sum_{i=0}^{m}z_iB_i(\tau)+s\delta\]
\[ C= \frac{\sum_{i=l+1}^{m}z_i(\beta A_i(\tau)+\alpha B_i(\tau)+C_i(\tau))+h(\tau)t(\tau)}{\delta} + As+Br-rs\delta\]
\(r,s\) is used to randomize proof generation to ensure the zero-knowledge property is satisfied. As shown, all elements in A are elements in \(\mathbb{G}_1\), such as \(\alpha=\alpha \cdot g_1\). Similarly, elements in B are in \(\mathbb{G}_2\)
- \(0,1 \leftarrow VFY(R, pk,x,\pi)\): The verifier accepts the proof \(\pi\) if and only if:
\[ \lbrack A \rbrack_{1} \cdot \lbrack B \rbrack_{2} = \lbrack \alpha \rbrack_{1} \cdot \lbrack \beta \rbrack_{2} + \sum_{i=0}^{l}z_i\lbrack \frac{\beta A_i(\tau) + \alpha B_i(\tau) + C_i(\tau)}{\gamma} \rbrack \cdot \lbrack \gamma \rbrack_2 + \lbrack C \rbrack_1 \cdot \lbrack \delta \rbrack_2 \]
Intuitively, \( \lbrack A \rbrack_{1} \cdot \lbrack B \rbrack_{2} \) represents the pairing \(e: \mathbb{G}_1 \times \mathbb{G}_2 \rightarrow \mathbb{G}_T\)
references
- [1] groth 16 paper, On the Size of Pairing-based Non-interactive Arguments by Jens Groth
- [2] 2022 Kaylee George, The Mathematical Mechanics Behind the Groth16 Zero-knowledge Proving Protocol
- [3] 2pi.com groth16