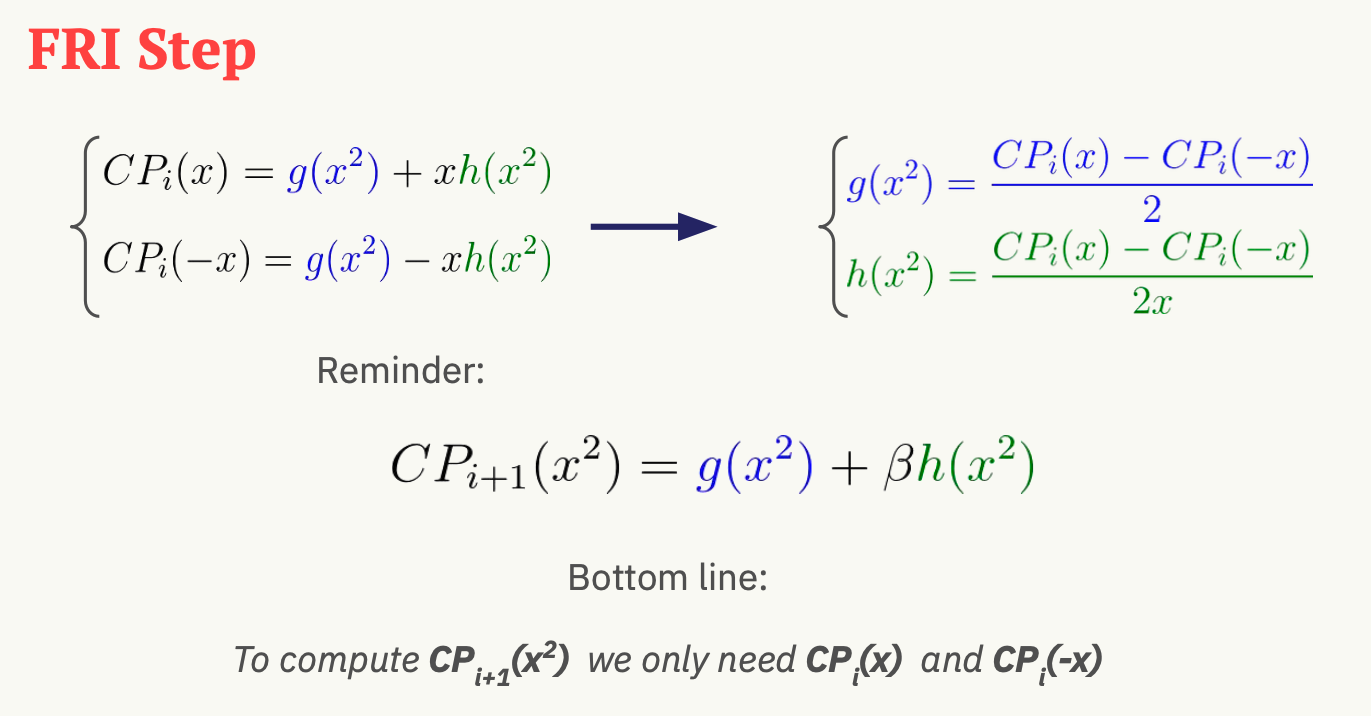
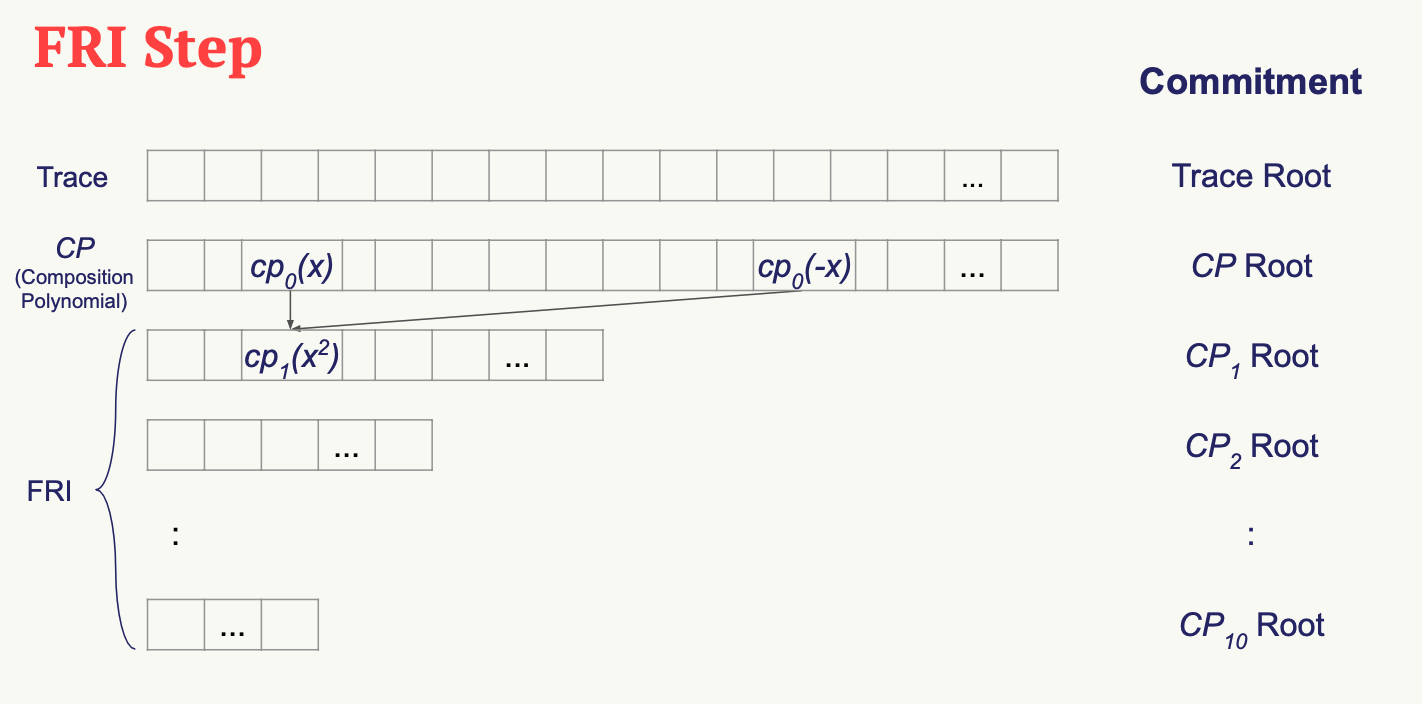
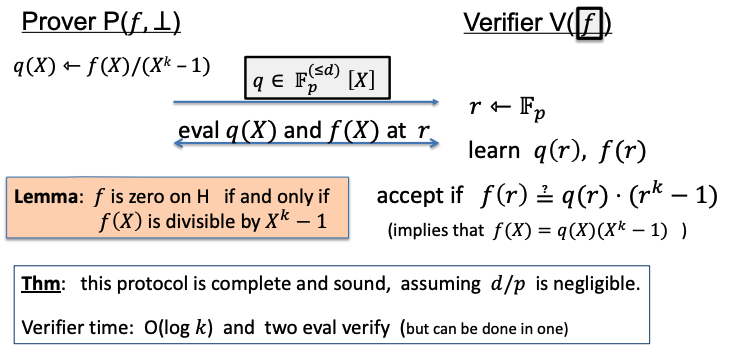
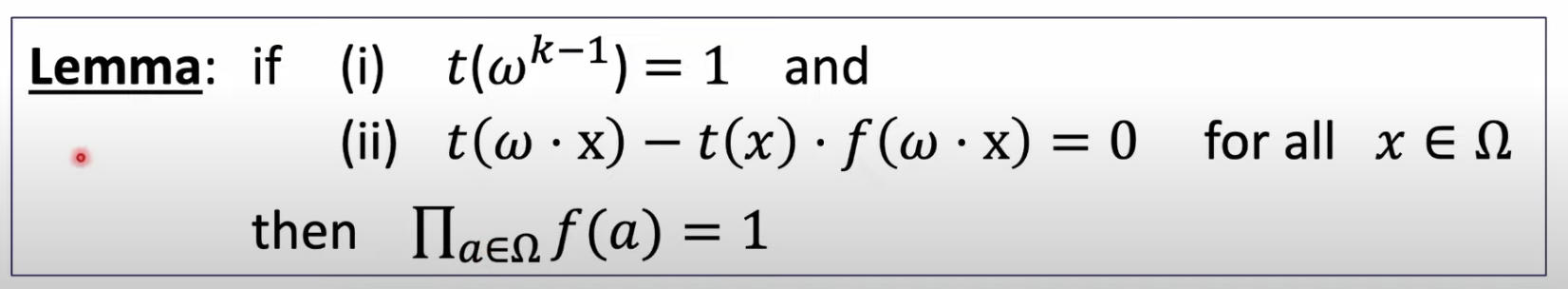Fourier Series
innter product of two functions
\[ <f(x), g(x)> = \int_{a}^{b} f(x) \bar{g}(x)dx\]
\(\bar{g}\) is the congugate of g on complex number system
Fourier series definition
let \(f(x)\) be a periodic function over a period of \([-\pi, +\pi]\)
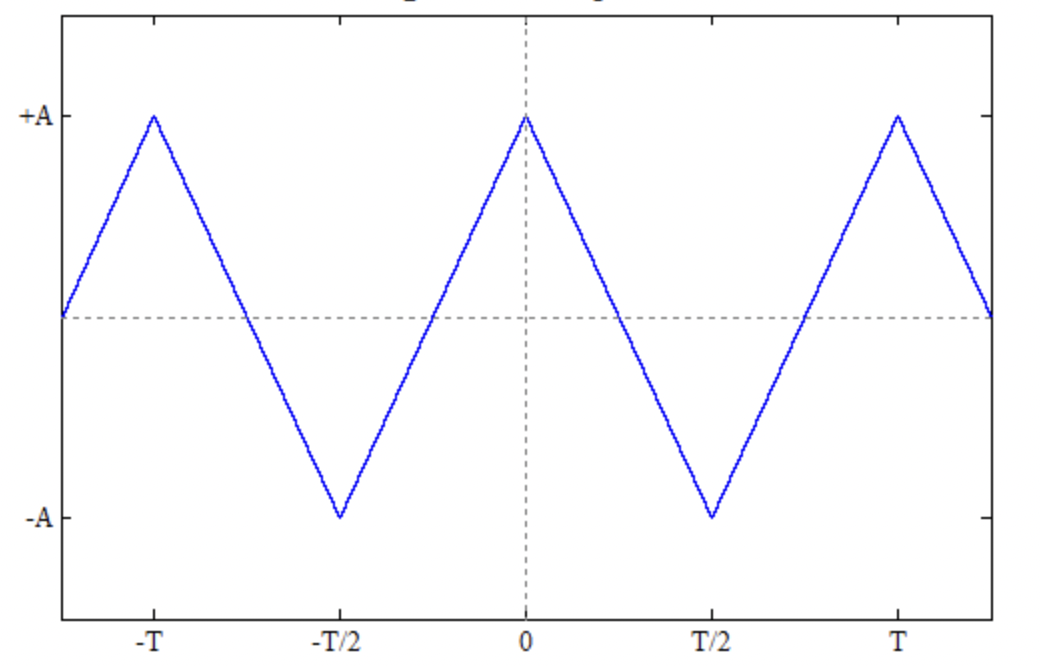
\( f(x) \) can be transformed into below
\[ f(x) = \frac{A_{0}}{2} + \sum_{k=1}^{\infty}A_{k}cos(kx) + B_{k}sin(kx)\],
where
\[ A_{k} = \frac{1}{\pi} \int_{-\pi}^{+\pi} f(x)cos(kx)dx = \frac{1}{||cos(kx)||^2}<f(x),cos(kx)> \]
\[ B_{k} = \frac{1}{\pi} \int_{-\pi}^{+\pi} f(x)sin(kx)dx = \frac{1}{||sin(kx)||^2}<f(x),sin(kx)> \]
where \(A_{k}, B_{k}\) is just the innver product of \(f(x)\), and \( cos(kx) \), \(sin(kx)\) respectively. intuitively, it is the projection of \(f(x)\) over \(sin(kx)\), or \(cos(kx)\).
if period is L
\[ f(x) = \frac{A_{0}}{2} + \sum_{k=1}^{\infty}A_{k}cos(\frac{2\pi kx}{L}) + B_{k}sin(\frac{2\pi kx}{L})\],
where
\[ A_{k} = \frac{2}{L} \int_{0}^{L} f(x)cos(\frac{2\pi kx}{L})dx\]
\[ B_{k} = \frac{2}{L} \int_{0}^{L} f(x)sin(\frac{2\pi kx}{L})dx\]
Complex Fourier Series
let’s define \[ \psi_k = e^{ikx} = cos(kx) + i \cdot sin(kx)\]
we can prove that \(\psi_k, and \psi_j\) are orthogonal as their inner product is zero
proof
\[ <\psi_j, \psi_k> = \int_{-\pi}^{+\pi} e^{jkx}e^{-ikx}dx = \int_{-\pi}^{+\pi} e^{j(j-k)x}dx = \frac{1}{i(j-k)}[e^{i(j-k)x}]_{-\pi}^{\pi}\]
it is 0 if \(j \ne k\) , \(2\pi \) if \(j=k\)
note conjugate of \(\psi_k\) is \(e^{-ikx}\)
\(f(x) = \frac{1}{2\pi} \sum_{k=-\infty}^{\infty} c_k \psi_k\), where \(c_k=<f(x), \psi_k> = \int_{-\pi}^{+\pi} f(x)e^{-ikx}dx\)
The discrete Fourier transform transforms a sequence of N complex numbers
\[\lbrace x_{n} \rbrace := x_0, x_1,…, x_{N-1} \] into another sequence of complex numbers,
\[\lbrace X_{k} \rbrace := X_0, X_1,…, X_{N-1} \] which is defined by
\[X_{k} = \sum_{n=0}^{N-1} x_{n} \cdot e^{-\frac{i2\pi}{N}kn}\]
let the n-th root of unity be \(\omega_N = e^{-\frac{2\pi i}{N}}\), we have
\[ \tag{1.1} X_{k} = \sum_{n=0}^{N-1} x_{n} \cdot \omega_N^{kn}\]
inverse DFT
The inverse transform is given by
\[ \tag{1.2} x_{n} = \frac{1}{N}\sum_{k=0}^{N-1} X_{k} \cdot \omega_N^{-kn}\]
the unitary DFT
Another way of looking at the DFT is to note that the DFT can be expressed as the DFT matrix, a Vandermonde matrix, introduced by Sylvester in 1867.
\[
\boldsymbol{F} =
\begin{bmatrix}
\displaylines{
\omega_{N}^{0\cdot0} & \omega_{N}^{0\cdot1} & \dots & \omega_{N}^{0\cdot (N-1)}\\
\omega_{N}^{1\cdot0} & \omega_{N}^{1\cdot1} & \dots & \omega_{N}^{2\cdot (N-1)}\\
\vdots & \vdots & \ddots & \vdots\\
\omega_{N}^{N-1\cdot0} & \omega_{N}^{N-1\cdot1} & \dots & \omega_{N}^{N-1\cdot (N-1)}
}
\end{bmatrix}
\]
where \( \omega_{N} = e^{-\frac{i2\pi}{N}}\) is a primitive Nth root of unity. (any complex number that yields 1 when raised to some positive integer power n)
\[ X = F \cdot x^{T}\]
\(x\) is a column vector
Polynomial & DFT
Polynomial evaluation & DFT
let a polynomial be
$$f(x)=\sum_{n=0}^{N-1}x_nx^n$$
then,
$$f(\omega_N^{k})=\sum_{n=0}^{N-1}x_n\omega_N^{kn},\quad k=0,1,2,…,N-1$$
compare this equation with E.q(1.1), we can know that DFT is the evaluations of a polynomial at N points of Nth root of unity, \(\omega_N^{0},\omega_N^1,\omega_N^2,…,\omega_N^{N-1}\)
$$(\omega_N^{0},X_0),(\omega_N^1,X_1),(\omega_N^2,X_2),…,(\omega_N^{N-1},X_{N-1})$$
Polynomial interpolation & IDFT
According to E.q(1.2), IDFT is the polynomial interpolation (getting original polynomial coefficients).
The problem is to calculate the below
\[ \tag{2.1} X_{k} = \sum_{n=0}^{N-1} x_{n} \cdot \omega_N^{kn}, \quad k= 0,1,…,N-1\]
A straightforward calculation using would require \(N^2\) operations where “operation” means, as it will throughout this note, a complex multiplication followed by a complex addition.
The FFT algorithm described here iterates on the array and yields the result in less than \( 2N log_2N \)
To derive the algorithm, suppose \(N\) is a composite, i.e., \(N = r_1\cdot r_2\). Then let the indices in (2.1) be expressed
\[ k = k_1r_1 + k_0, \quad k_0 = 0,1,…,r_1-1, \quad k_1 = 0,1,…, r_2 -1 \]
\[ n = n_1r_2 + n_0, \quad n_0 = 0,1,…,r_2-1, \quad n_1 = 0,1,…, r_1 -1 \]
Since \( n = n_1r_2 + n_0\), we can write
\[ \tag{2.2} X(k_1, k_0) = \sum_{n_0} \sum_{n_1}x(n_1,n_0)\omega_N^{kn} = \sum_{n_0} \sum_{n_1}x(n_1,n_0)\omega_N^{kn_1r_2}\omega_N^{kn_0} \]
note \( x(n_1,n_0)\) is same to \(x(n)\), just the indexing is transformed form 1D to 2D. You can think original 1D array of size N is resized to a matrix of size \( (r_2, r_1) \), \(r_1\) is number of cols, while \(r_2\) is number of rows
Since \(k = k_1r_1 + k_0\), we have
\[ \omega_N^{kn_1r_2} =\omega_N^{(k_1r_1+k_0)n_1r_2} = \omega_N^{(k_1r_1)n_1r_2} \cdot \omega_N^{k_0n_1r_2}\]
according to the property of Nth root of unity, \( \omega_N^{N} = \omega_N^{r_1r_2} =1 \), \( \omega_N^{(k_1r_1)n_1r_2}\) is also 1.
then we have
\[ \omega_N^{kn_1r_2} = \omega_N^{k_0n_1r_2}\]
substitute it into E.q 2.2, we get
\[ \tag{2.3} X(k_1, k_0) = \sum_{n_0} \sum_{n_1}x(n_1,n_0)\omega_N^{kn} = \sum_{n_0} \sum_{n_1}x(n_1,n_0)\omega_N^{k_0n_1r_2}\omega_N^{kn_0} \]
Therefore, the inner sum, over \(n_1\), depends only on \(k_0\) and \(n_0\), and can be defined as a new array,
\[ \tag{2.4} x_1(k_0, n_0) = \sum_{n_1} x(n_1, n_0) \cdot \omega_N^{k_0n_1r_2}\]
E.q(2.3) can be writtern as
\[ \tag{2.5} X(k_1, k_0) = \sum_{n_0} x_1(k_0,n_0)\omega_N^{kn_0} = \sum_{n_0} x_1(k_0,n_0)\omega_N^{(k_1r_1 + k_0)n_0} \]
There are N elements in the matrix \(x_1\), each requiring \(r_1\) operations, giving a total of \(Nr_1\) operations. Similarly, it takes \(Nr_2\) operations to calculate \(X\) from \(x_1\). Therefore, the two-step algorithm, given by Eq(2.4) and Eq(2.5) requires a total of
\[ \tag{2.6} T = N(r_1+r_2) \]
it is easy to see how successive applications of the above procedure (recursively), starting with its appliation to Eq(2.4) give an m-step algorihtm requiring
\[ \tag{2.7} T = N(r_1+r_2 + … + r_m) \]
where
\[ N = \prod_{j=1}^{j=m}r_j\]
if all \(r_j\) are equal to \(r\), i.e \(N = r^m \), which gives \( m = log_rN \)
E.q(2.7) becomes
\[ \tag{2.8} T = N(m \cdot r) = rNm = rN(log_rN) \]
radix-2 FFT
The algorithm with \(r=2\) is derived by expressing the indices in the form
\[\tag{3.1} k=k_{m-1} \cdot 2^{m-1} + … + k_1 \cdot 2 + k_0 \]
\[\tag{3.2} n=n_{m-1} \cdot 2^{m-1} + … + n_1 \cdot 2 + n_0 \]
where \( k_v \in [0,1] \), for \( v = 0,…,m-1 \), and \( n_v \in [0,1] \), for \( v = 0,…,m-1 \)
\(k_v\) and \(n_v\) are the contents of the respective bit positions in the binary representation of \(k\) and \(n\)
All arrays will now be written as functions of the bits of their indices. With this convention E.q(2.1) is written as
\[ \tag{3.3}
\displaylines{
X(k_{m-1}, …, k_0) = \sum_{n_0}\sum_{n_1} … \sum_{n_{m-1}} x(n_{m-1}, …,n_1, n_0) \cdot \omega_N^{kn} \\
= \sum_{n_0}\sum_{n_1} … \sum_{n_{m-1}} x(n_{m-1}, …,n_1, n_0) \cdot \omega_N^{k(n_{m-1} \cdot 2^{m-1} + … + n_1 \cdot 2 + n_0)} \\
= \sum_{n_0}\sum_{n_1} … \sum_{n_{m-1}} x(n_{m-1}, …,n_1, n_0) \cdot \omega_N^{kn_{m-1} \cdot 2^{m-1} + … + kn_1 \cdot 2 + kn_0}
}
\]
where the sums are over \(n_v \in [0,1]\), for \(v = 0,1,…,m-1\)
Since \[ \displaylines{
\omega_N^{kn_{m-1}\cdot 2^{m-1}} = \omega_N^{(k_{m-1} \cdot 2^{m-1} + … + k_1 \cdot 2 + k_0)n_{m-1}\cdot 2^{m-1}} \\
= \omega_N^{k_0 n_{m-1} \cdot 2^{m-1}}
}
\]
(it is easy to show that all other terms are 1 as \( \omega_N^{2^m} = 1 \), so only \( k_0\) is kept)
the innermost sum of E.q(3.3) over \(n_{m-1} \), depends only on \( k_0, n_{m-2}, …, n_0\) and can be writtern
\[ \displaylines{
x_1(k_0, n_{m-2}, …, n_1, n_0) = \sum_{n_{m-1}} x(n_{m-1}, …, n_0) \cdot \omega_N^{k_0 n_{m-1} \cdot 2^{m-1}}
}
\]
proceeding to the next innermost sum, over \( n_{m-2} \), and so on, and using
\[ \displaylines{
\omega_N^{kn_{m-l}\cdot 2^{m-l}} = \omega_N^{(k_{m-1} \cdot 2^{m-1} + … + k_1 \cdot 2 + k_0)n_{m-l}\cdot 2^{m-l}} \\
= \omega_N^{(k_{l-1}\cdot 2^{l-1} + … + k_0) n_{m-l} \cdot 2^{m-1}}
}
\]
one obtains successive arrays
\[\displaylines{
x_l(k_0, …, k_{l-1}, n_{m-l-1}, … , n_0) \\
= \sum_{n_{m-l}}x_{l-1}(k_0, …, k_{l-2}, n_{m-l}, …, n_0 ) \cdot \omega_N^{(k_{l-1}\cdot 2^{l-1} + …+ k_0) \cdot n_{m-l} \cdot 2^{m-l}}
}\]
for \(l = 1,2,…,m \)
writing out the sum this appears as
\[ \tag{3.4} \displaylines{
x_l(k_0, …, k_{l-1}, n_{m-l-1}, … , n_0) \\
= x_{l-1}(k_0, …, k_{l-2}, 0, n_{m-l -1}, …, n_0 ) \cdot \omega_N^{(k_{l-1}\cdot 2^{l-1} + …+ k_0) \cdot 0 \cdot 2^{m-l}} \\
+ x_{l-1}(k_0, …, k_{l-2}, 1, n_{m-l -1}, …, n_0 ) \cdot \omega_N^{(k_{l-1}\cdot 2^{l-1} + …+ k_0) \cdot 1 \cdot 2^{m-l}} \\
= x_{l-1}(k_0, …, k_{l-2}, 0, n_{m-l -1}, …, n_0 ) \\
+ x_{l-1}(k_0, …, k_{l-2}, 1, n_{m-l-1}, …, n_0 ) \cdot \omega_N^{(k_{l-1}\cdot 2^{l-1} + k_{l-2}\cdot 2^{l-2 }+k_{l-3}\cdot 2^{l-3} + …+ k_0) \cdot 2^{m-l}} \\
= x_{l-1}(k_0, …, k_{l-2}, 0, n_{m-l -1}, …, n_0 ) \\
+ \omega_N^{k_{l-1}\cdot 2^{l-1} \cdot 2^{m-l} } \cdot \omega_N^{k_{l-2}\cdot 2^{l-2 } \cdot 2^{m-l}} \cdot x_{l-1}(k_0, …, k_{l-2}, 1, n_{m-l-1}, …, n_0 ) \cdot \omega_N^{(k_{l-3}\cdot 2^{l-3} + …+ k_0) \cdot 2^{m-l}} \\
= x_{l-1}(k_0, …, k_{l-2}, 0, n_{m-l -1}, …, n_0 ) \\
+ \omega_N^{k_{l-1}\cdot 2^{m-1} } \cdot \omega_N^{k_{l-2}\cdot 2^{m-2}} \cdot x_{l-1}(k_0, …, k_{l-2}, 1, n_{m-l-1}, …, n_0 ) \cdot \omega_N^{(k_{l-3}\cdot 2^{l-3} + …+ k_0) \cdot 2^{m-l}} \\
= x_{l-1}(k_0, …, k_{l-2}, 0, n_{m-l -1}, …, n_0 ) \\
+ (-1)^{k_{l-1} } \cdot i^{k_{l-2}} \cdot x_{l-1}(k_0, …, k_{l-2}, 1, n_{m-l-1}, …, n_0 ) \cdot \omega_N^{(k_{l-3}\cdot 2^{l-3} + …+ k_0) \cdot 2^{m-l}}
}\]
according to the indexing convension, this is stored in a location whose index is
\[ k_0 \cdot 2^{m-1} + … + k_{l-1} \cdot 2 ^{m-l} + n_{m-l-1} \cdot 2^{m-l-1} + … + n_0 \]
It can be seen in E.q(3.4) that only the two storage locations with indices having 0 and 1 in the \(2^{m-l}\) bit position are involved in the computation. Parallel computation is permitted since the operation described by E.q(3.4) can be carried out with all values of \(k_0, …, k_{l-2} \), and \( n_0, …, n_{m-l-1}\) simultaneously. In some applications it is convenient to use E.q(3.4) to express \(x_l\) in terms of \(x_{l-2}\), giving what is equivalent to an algorithm with \(r = 4\).
the last array calculated gives the desired Fourier sums,
\[\tag{3.5}
X(k_{m-1}, …, k_0) = x_{m}(k_0, …, k_{m-1})
\]
in such an order that the index of an X must have its binary bits put in reverse order to yield its index in the array \(x_m\)
references