Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
ref annotates pattern bindings to make them borrow rather than move. It is not a part of the pattern as far as matching is concerned: it does not affect whether a value is matched, only how it is matched. By default, match statements consume all they can, which can sometimes be a problem, when you don’t really need the value to be moved and owned:
1 2 3 4 5 6 7 8
letmaybe_name = Some(String::from("Alice")); // Using `ref`, the value is borrowed, not moved ... match maybe_name { Some(ref n) => println!("Hello, {n}"), _ => println!("Hello, world"), } // ... so it's available here! println!("Hello again, {}", maybe_name.unwrap_or("world".into()));
& denotes that your pattern expects a reference to an object. Hence & is a part of said pattern: &Foo matches different objects than Foo does.
ref indicates that you want a reference to an unpacked value. It is not matched against: Foo(ref foo) matches the same objects as Foo(foo).
// Positional arguments can be used println!("{0}, this is {1}. {1}, this is {0}", "Alice", "Bob"); // As can named arguments. println!("{subject} {verb} {object}", object="the lazy dog", subject="the quick brown fox", verb="jumps over"); // Different formatting can be invoked by specifying the format character // after a `:`. println!("Base 10: {}", 69420); // 69420 println!("Base 2 (binary): {:b}", 69420); // 10000111100101100 println!("Base 8 (octal): {:o}", 69420); // 207454 println!("Base 16 (hexadecimal): {:x}", 69420); // 10f2c println!("Base 16 (hexadecimal): {:X}", 69420); // 10F2C // You can right-justify text with a specified width. This will // output " 1". (Four white spaces and a "1", for a total width of 5.) println!("{number:>5}", number=1); // You can pad numbers with extra zeroes, // and left-adjust by flipping the sign. This will output "10000". println!("{number:0<5}", number=1); // You can use named arguments in the format specifier by appending a `$`. println!("{number:0>width$}", number=1, width=5);
#![allow(warnings)] #[allow(dead_code)] #![allow(unused)] // Suppress all warnings from casts which overflow. #![allow(overflowing_literals)] #![allow(unreachable_code)]
/// adds one to the number given /// /// # Examples /// ``` /// let arg = 5; /// let answer = my_crate::add_one(arg); /// /// assert_eq!(6, answer); /// ``` pubfnadd_one(x: i32) ->i32 { x + 1; }
package rpc implements bi-directional JSON-RPC 2.0 on multiple transports (http, ws, ipc). After creating a server or client instance, objects can be registered to make them visible as ‘services’. Exported methods that follow specific conventions can be called remotely. It also has support for the publish/subscribe pattern.
methods
rpc endpoints (callback)
Methods that satisfy the following criteria are made available for remote access:
method must be exported
method returns 0, 1 (response or error) or 2 (response and error) values
The server offers the ServeCodec method which accepts a ServerCodec instance. It will read requests from the codec, process the request and sends the response back to the client using the codec. The server can execute requests concurrently. Responses can be sent back to the client out of order.
An example server which uses the JSON codec:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
type CalculatorService struct {}
func(s *CalculatorService) Add(a, b int) int { return a + b }
func(s *CalculatorService) Div(a, b int) (int, error) { if b == 0 { return0, errors.New("divide by zero") } return a/b, nil }
The package also supports the publish subscribe pattern through the use of subscriptions. A method that is considered eligible for notifications must satisfy the following criteria:
method must be exported
first method argument type must be context.Context
method must have return types (rpc.Subscription, error)
In any method handler, an instance of rpc.Client can be accessed through the ClientFromContext method. Using this client instance, server-to-client method calls can be performed on the RPC connection.
server
to start rpc service, the invoking chain is as below
use std::io; use std::io::Write; use std::io:: { self, Write} ; use std::{cmp::Ordering, io}; use std::fmt::Result; use std::io::Resultas IoResult; use std::collections::*;
pubuse crate::front_of_house::hosting; // re-exporting names with pub use
# profile for the wasm example (from project ethers-rs) [profile.release.package.ethers-wasm] opt-level = "s" # Tell `rustc` to optimize for small code size.
git clone https://github.com/ethereum/go-ethereum.git cd go-ethereum make geth
understanding geth config
geth config type is defined in /cmd/geth/config.go
1 2 3 4 5 6
type gethConfig struct { Eth ethconfig.Config Node node.Config Ethstats ethstatsConfig Metrics metrics.Config }
ethconfig (eth/ethconfig/config.go) contains configuration options for of the ETH and LES(light node) protocols, such as NetworkId, SyncMode, txpool.Config, database options
nodeConfig (node/config.go) represents a small collection of configuration values to fine tune the P2P network layer of a protocol stack. These values can be further extended by all registered services. such as p2p.Config, DataDir, KeyStoreDir, HTTPHost, HTTPModules(eth,net,web3), WSHost
metrics.Config (metrics/config.go) contains the configuration for the metric collection, such as InfluxDBEndpoint, etc
ethstatsConfig only one URL entry
geth provides default config in the above files. user config file path is given by the below flag
The config file should be a .toml file. A convenient way to create a config file is to get Geth to create one for you and use it as a template. To do this, use the dumpconfig command, saving the result to a .toml file. Note that you also need to explicitly provide the network_id on the command line for the public testnets such as Sepolia or Geoerli:
1
./geth --sepolia dumpconfig > geth-config.toml
to specify path to config file
1
geth --sepolia --config geth-config.toml
key configs
[Eth].TxLookupLimit Number of recent blocks to maintain transactions index for (default = about one year, 0 = entire chain), default: 2350000
[Node].BootstrapNodes used to establish connectivity with the rest of the network. geth provides default bootstrapNodes in file params/bootnodes.go
[Metrics_AND_STATS].ethstats Reporting URL of a ethstats service (nodename:secret@host:port), more detail
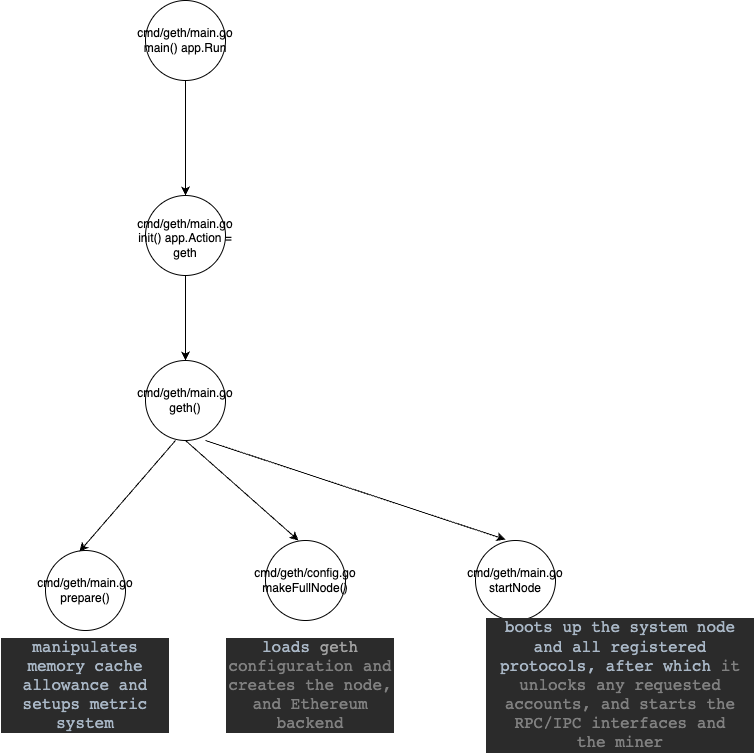
the main() function is very short, and its main function is to start a tool for parsing command line commands: gopkg.in/urfave/cli.v1. Going deeper, we will find that app.Action = geth will be called when the cli app is initialized to call the geth() function
1 2 3 4 5
funcinit() { // Initialize the CLI app and start Geth app.Action = geth // .... }
geth is the main entry point into the system if no special subcommand is run. It creates a default node based on the command line arguments and runs it in blocking mode, waiting for it to be shut down.
In the geth() function, there are three important function calls, namely: prepare(), makeFullNode(), and startNode().
prepare
The implementation of the prepare() function is in the current main.go file. It is mainly used to set some configurations required for node initialization.
makeFullNode
The implementation of the makeFullNode() function is located in the cmd/geth/config.go file. It will load the context of the command and apply user given configuration; and generate instances of stack and backend. Among them, stack is an instance of Node type (Node is the top-level instance in the life cycle of geth. It is responsible for managing high-level abstractions such as P2P Server, Http Server, and Database in the node. The definition of the Node type is located in the node/node.go file), which is initialized by calling makeConfigNode() function through makeFullNode() function. inside makeFullNode, it calls node.New(&cfg.Node) to initiate a node. During instantiating of node, it invokes rpc.NewServer() to create a new rpc server and put in the field inprocHandler. it registers rpc api namespace by default.
The backend here is an interface of ethapi.Backend type, which provides the basic functions needed to obtain the runtime of the Ethereum execution layer. Its definition is located in internal/ethapi/backend.go. Since there are many functions in this interface, we have selected some of the key functions as below for a glimpse of its functionality. backend is created by calling backend, eth := utils.RegisterEthService(stack, &cfg.Eth). Inside, it calls eth.New(stack, cfg) to create backend instance. During backend initiating, it opens database (chainDb, err := stack.OpenDatabaseWithFreezer("chaindata", config.DatabaseCache, config.DatabaseHandles, config.DatabaseFreezer, "eth/db/chaindata/", false)). Further, it creates consensus engine, engine := ethconfig.CreateConsensusEngine(stack, ðashConfig, cliqueConfig, config.Miner.Notify, config.Miner.Noverify, chainDb). goerli testnet use POA consensus (clique).
type Backend interface { SyncProgress() ethereum.SyncProgress SuggestGasTipCap(ctx context.Context) (*big.Int, error) ChainDb() ethdb.Database AccountManager() *accounts.Manager ExtRPCEnabled() bool RPCGasCap() uint64// global gas cap for eth_call over rpc: DoS protection RPCEVMTimeout() time.Duration // global timeout for eth_call over rpc: DoS protection RPCTxFeeCap() float64// global tx fee cap for all transaction related APIs UnprotectedAllowed() bool// allows only for EIP155 transactions. SetHead(number uint64) HeaderByNumber(ctx context.Context, number rpc.BlockNumber) (*types.Header, error) HeaderByHash(ctx context.Context, hash common.Hash) (*types.Header, error) HeaderByNumberOrHash(ctx context.Context, blockNrOrHash rpc.BlockNumberOrHash) (*types.Header, error) CurrentHeader() *types.Header CurrentBlock() *types.Header BlockByNumber(ctx context.Context, number rpc.BlockNumber) (*types.Block, error) BlockByHash(ctx context.Context, hash common.Hash) (*types.Block, error) BlockByNumberOrHash(ctx context.Context, blockNrOrHash rpc.BlockNumberOrHash) (*types.Block, error) StateAndHeaderByNumber(ctx context.Context, number rpc.BlockNumber) (*state.StateDB, *types.Header, error) StateAndHeaderByNumberOrHash(ctx context.Context, blockNrOrHash rpc.BlockNumberOrHash) (*state.StateDB, *types.Header, error) PendingBlockAndReceipts() (*types.Block, types.Receipts) GetReceipts(ctx context.Context, hash common.Hash) (types.Receipts, error) GetTd(ctx context.Context, hash common.Hash) *big.Int GetEVM(ctx context.Context, msg *core.Message, state *state.StateDB, header *types.Header, vmConfig *vm.Config) (*vm.EVM, func()error, error) SubscribeChainEvent(ch chan<- core.ChainEvent) event.Subscription SubscribeChainHeadEvent(ch chan<- core.ChainHeadEvent) event.Subscription SubscribeChainSideEvent(ch chan<- core.ChainSideEvent) event.Subscription SendTx(ctx context.Context, signedTx *types.Transaction) error GetTransaction(ctx context.Context, txHash common.Hash) (*types.Transaction, common.Hash, uint64, uint64, error) GetPoolTransactions() (types.Transactions, error) GetPoolTransaction(txHash common.Hash) *types.Transaction GetPoolNonce(ctx context.Context, addr common.Address) (uint64, error) Stats() (pending int, queued int) TxPoolContent() (map[common.Address]types.Transactions, map[common.Address]types.Transactions) TxPoolContentFrom(addr common.Address) (types.Transactions, types.Transactions) SubscribeNewTxsEvent(chan<- core.NewTxsEvent) event.Subscription ChainConfig() *params.ChainConfig Engine() consensus.Engine GetBody(ctx context.Context, hash common.Hash, number rpc.BlockNumber) (*types.Body, error) GetLogs(ctx context.Context, blockHash common.Hash, number uint64) ([][]*types.Log, error) SubscribeRemovedLogsEvent(ch chan<- core.RemovedLogsEvent) event.Subscription SubscribeLogsEvent(ch chan<- []*types.Log) event.Subscription SubscribePendingLogsEvent(ch chan<- []*types.Log) event.Subscription BloomStatus() (uint64, uint64) ServiceFilter(ctx context.Context, session *bloombits.MatcherSession) }
If readers want to customize some new RPC APIs, they can define functions in the /internal/ethapi.Backend interface and add specific implementations to EthAPIBackend
startNode
The last key function, startNode(), is to officially start an Ethereum execution layer node. It starts the Stack instance (Node) by calling the utils.StartNode() function which triggers the Node.Start() function. In the Node.Start() function, it traverses the backend instances registered in Node.lifecycles and starts them. In addition, in the startNode() function, the unlockAccounts() function is still called, and the unlocked wallet is registered in the stack, and the RPClient module that interacts with local Geth is created through the stack.Attach() function
At the end of the geth() function, the function executes stack.Wait(), so that the main thread enters the blocking state, and the services of other functional modules are distributed to other sub-coroutines for maintenance
Node
As we mentioned earlier, the Node type belongs to the top-level instance in the life cycle of geth, and it is responsible for being the administrator of the high-level abstract module communicating with the outside world, such as managing rpc server, http server, Web Socket, and P2P Server external interface . At the same time, Node maintains the back-end instances and services (lifecycles []Lifecycle) required for node operation, such as the Ethereum type we mentioned above that is responsible for the specific Service
type Node struct { eventmux *event.TypeMux config *Config accman *accounts.Manager log log.Logger keyDir string// key store directory keyDirTemp bool// If true, key directory will be removed by Stop dirLock *flock.Flock // prevents concurrent use of instance directory stop chanstruct{} // Channel to wait for termination notifications server *p2p.Server // Currently running P2P networking layer startStopLock sync.Mutex // Start/Stop are protected by an additional lock state int// Tracks state of node lifecycle
lock sync.Mutex lifecycles []Lifecycle // All registered backends, services, and auxiliary services that have a lifecycle rpcAPIs []rpc.API // List of APIs currently provided by the node http *httpServer // ws *httpServer // httpAuth *httpServer // wsAuth *httpServer // ipc *ipcServer // Stores information about the ipc http server inprocHandler *rpc.Server // In-process RPC request handler to process the API requests
databases map[*closeTrackingDB]struct{} // All open databases }
close node
As mentioned earlier, the main thread of the entire program is blocked because of calling stack.Wait(). We can see that a channel called stop is declared in the Node structure. Since this Channel has not been assigned a value, the main process of the entire geth enters the blocking state, and continues to execute other business coroutines concurrently
1 2 3 4
// Wait blocks until the node is closed. func(n *Node) Wait() { <-n.stop }
When the Channel n.stop is assigned a value, the geth main function will stop the current blocking state and start to perform a series of corresponding resource release operations. It is worth noting that in the current codebase of go-ethereum, the blocking state of the main process is not ended directly by assigning a value to the stop channel, but a more concise and rude way is used: call the close() function directly Close the Channel. We can find the related implementation in node.doClose(). close() is a native function of go language, used when closing Channel.
// doClose releases resources acquired by New(), collecting errors. func(n *Node) doClose(errs []error) error { // Close databases. This needs the lock because it needs to // synchronize with OpenDatabase*. n.lock.Lock() n.state = closedState errs = append(errs, n.closeDatabases()...) n.lock.Unlock()
if err := n.accman.Close(); err != nil { errs = append(errs, err) } if n.keyDirTemp { if err := os.RemoveAll(n.keyDir); err != nil { errs = append(errs, err) } }
// Report any errors that might have occurred. switchlen(errs) { case0: returnnil case1: return errs[0] default: return fmt.Errorf("%v", errs) } }
Ethereum Backend
We can find the definition of the Ethereum structure in eth/backend.go. The member variables and receiving methods contained in this structure implement all the functions and data structures required by an Ethereum full node. We can see in the following code definition that the Ethereum structure contains several core data structures such as TxPool, Blockchain, consensus.Engine, and miner as member variables.
lock sync.RWMutex // Protects the variadic fields (e.g. gas price and etherbase)
shutdownTracker *shutdowncheck.ShutdownTracker // Tracks if and when the node has shutdown ungracefully }
Nodes start and stop Mining by calling Ethereum.StartMining() and Ethereum.StopMining(). Setting the profit account of Mining is achieved by calling Ethereum.SetEtherbase() Here we pay extra attention to the member variable handler. The definition of handler is in eth/handler.go. From a macro point of view, the main workflow of a node needs to: 1. Obtain/synchronize Transaction and Block data from the network 2. Add the Block obtained from the network to the Blockchain. The handler is responsible for providing the function of synchronizing blocks and transaction data, for example, downloader.Downloader is responsible for synchronizing Block from the network, and fetcher.TxFetcher is responsible for synchronizing transactions from the network
The most common kind of pointer in Rust is a reference (borrow but not own) Smart pointers, on the other hand, are data structures that not only act like a pointer but also have additional metadata and capabilities. references are pointers that only borrow data; in contrast, in many cases, smart pointers own the data they point to.
smart pointers example
String
Vec Both these types count as smart pointers because they own some memory and allow you to manipulate it. They also have metadata (such as their capacity) and extra capabilities or guarantees (such as with String ensuring its data will always be valid UTF-8).
Deref & Drop
Smart pointers are usually implemented using structs. The characteristic that distinguishes a smart pointer from an ordinary struct is that smart pointers implement the Deref and Drop traits.
The Deref trait allows an instance of the smart pointer struct to behave like a reference so you can write code that works with either references or smart pointers.
The Drop trait allows you to customize the code that is run when an instance of the smart pointer goes out of scope.
the most common smart pointers in the standard library:
Box<T> for allocating values on the heap
Rc<T>, a reference counting type that enables multiple ownership
Ref<T> and RefMut<T>, accessed through RefCell<T>, a type that enforces the borrowing rules at runtime instead of compile time
Box
when to use
When you have a type whose size can’t be known at compile time and you want to use a value of that type in a context that requires an exact size. (such as cons)
When you have a large amount of data and you want to transfer ownership but ensure the data won’t be copied when you do so
When you want to own a value and you care only that it’s a type that implements a particular trait rather than being of a specific type
enabling recursive types with Box
At compile time, Rust needs to know how much space a type takes up One type whose size can’t be known at compile time is a recursive type (cons list), use Box, which only contains a memory address
1 2 3 4 5 6 7 8 9
enumList { Cons(i32, List), Nil, }
use crate::List::{Cons, Nil}; fnmain() { letlist = Cons(1, Cons(2, Cons(3, Nil))); // not allowed, infinite size }
Treating Smart Pointers Like Regular References with the Deref Trait
Implementing the Deref trait allows you to customize the behavior of the dereference operator, * By implementing Deref in such a way that a smart pointer can be treated like a regular reference, you can write code that operates on references and use that code with smart pointers too.
We fill in the body of the deref method with &self.0 so deref returns a reference to the value we want to access with the * operator.
behind the scenes Rust actually ran this code: *(y.deref()). Rust substitutes the * operator with a call to the deref method
The reason the deref method returns a reference to a value, and that the plain dereference outside the parentheses in *(y.deref()) is still necessary, is the ownership system. If the deref method returned the value directly instead of a reference to the value, the value would be moved out of self. We don’t want to take ownership of the inner value inside MyBox in this case or in most cases where we use the dereference operator.
Implicit Deref Coercions with Functions and Methods
Deref coercion is a convenience that Rust performs on arguments to functions and methods. Deref coercion works only on types that implement the Deref trait. Deref coercion converts a reference to such a type into a reference to another type. For example, deref coercion can convert &String to &str because String implements the Deref trait such that it returns &str A sequence of calls to the deref method converts the type we provided into the type the parameter needs.
fnmain() { letm = MyBox::new(String::from("Rust")); hello("rust"); // ok hello(&m); // also ok hello(&(*m)[..]); // without deref coercion. The (*m) dereferences the MyBox<String> into a String. Then the & and [..] take a string slice of the String that is equal to the whole string to match the signature of hello }
Here we’re calling the hello function with the argument &m, which is a reference to a MyBox value. Because we implemented the Deref trait on MyBox, Rust can turn &MyBox into &String by calling deref. The standard library provides an implementation of Deref on String that returns a string slice. Rust calls deref again to turn the &String into &str, which matches the hello function’s definition.
How Deref Coercion Interacts with Mutability
Similar to how you use the Deref trait to override the * operator on immutable references, you can use the DerefMut trait to override the * operator on mutable references.
Rust does deref coercion when it finds types and trait implementations in three cases:
From &T to &U when T: Deref<Target=U>
From &mut T to &mut U when T: DerefMut<Target=U>
From &mut T to &U when T: Deref<Target=U>
Running Code on Cleanup with the Drop Trait
Drop, which lets you customize what happens when a value is about to go out of scope.
implDropforCustomSmartPointer { fndrop(&mutself) { println!("Dropping CustomSmartPointer with data `{}`!", self.data); } }
fnmain() { letc = CustomSmartPointer { data: String::from("some data"), }; println!("CustomSmartPointer created."); drop(c); // ok println!("CustomSmartPointer dropped before the end of main."); } // c goes out of scope, will occur double drop
Rc: the Reference Counted Smart Pointer
In the majority of cases, ownership is clear: you know exactly which variable owns a given value. However, there are cases when a single value might have multiple owners. type keeps track of the number of references to a value to determine whether or not the value is still in use. If there are zero references to a value, the value can be cleaned up without any references becoming invalid.
We use the Rc<T> type when we want to allocate some data on the heap for multiple parts of our program to read and we can’t determine at compile time which part will finish using the data last.
Rc is only for use in single-threaded scenarios
using Rc to share data
implement use box will not work, as below
1 2 3 4 5 6 7 8 9 10 11 12
enumList { Cons(i32, Box<List>), Nil, }
use crate::List::{Cons, Nil};
fnmain() { leta = Cons(5, Box::new(Cons(10, Box::new(Nil)))); letb = Cons(3, Box::new(a)); // value moved here letc = Cons(4, Box::new(a)); // value used here after move }
use Rc
1 2 3 4 5 6 7 8 9 10 11 12 13
enumList { Cons(i32, Rc<List>), Nil, }
use crate::List::{Cons, Nil}; use std::rc::Rc;
fnmain() { leta = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); letb = Cons(3, Rc::clone(&a)); // shalow copy only reference, not data letc = Cons(4, Rc::clone(&a)); }
We could have called a.clone() rather than Rc::clone(&a), but Rust’s convention is to use Rc::clone in this case. The implementation of Rc::clone doesn’t make a deep copy of all the data like most types’ implementations of clone do. The call to Rc::clone only increments the reference count, which doesn’t take much time.
Cloning an Rc Increases the Reference Count
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
enumList { Cons(i32, Rc<List>), Nil, }
use crate::List::{Cons, Nil}; use std::rc::Rc;
fnmain() { leta = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); println!("count after creating a = {}", Rc::strong_count(&a)); // 1 letb = Cons(3, Rc::clone(&a)); println!("count after creating b = {}", Rc::strong_count(&a)); // 2 { letc = Cons(4, Rc::clone(&a)); println!("count after creating c = {}", Rc::strong_count(&a)); // 3 } println!("count after c goes out of scope = {}", Rc::strong_count(&a)); // 2 }
What we can’t see in this example is that when b and then a go out of scope at the end of main, the count is then 0, and the Rc is cleaned up completely at that point.
RefCell and interior mutability pattern
Interior mutability is a design pattern in Rust that allows you to mutate data even when there are immutable references to that data; normally, this action is disallowed by the borrowing rules. To mutate data, the pattern uses unsafe code inside a data structure to bend Rust’s usual rules that govern mutation and borrowing. We can use types that use the interior mutability pattern when we can ensure that the borrowing rules will be followed at runtime, even though the compiler can’t guarantee that. The unsafe code involved is then wrapped in a safe API, and the outer type is still immutable.
Enforcing Borrowing Rules at Runtime with RefCell
Unlike Rc, the RefCell type represents single ownership over the data it holds.
recall borrowing rules
At any given time, you can have either (but not both of) one mutable reference or any number of immutable references.
References must always be valid. With references and Box, the borrowing rules’ invariants are enforced at compile time. With RefCell, these invariants are enforced at runtime. Because RefCell allows mutable borrows checked at runtime, you can mutate the value inside the RefCell even when the RefCell is immutable.
Interior Mutability: A Mutable Borrow to an Immutable Value
1 2 3 4
fnmain() { letx = 5; lety = &mut x; // not allowed. cannot borrow `x` as mutable, as it is not declared as mutable }
if percentage_of_max >= 1.0 { self.messenger.send("Error: You are over your quota!"); } elseif percentage_of_max >= 0.9 { self.messenger .send("Urgent warning: You've used up over 90% of your quota!"); } elseif percentage_of_max >= 0.75 { self.messenger .send("Warning: You've used up over 75% of your quota!"); } } }
if percentage_of_max >= 1.0 { self.messenger.send("Error: You are over your quota!"); } elseif percentage_of_max >= 0.9 { self.messenger .send("Urgent warning: You've used up over 90% of your quota!"); } elseif percentage_of_max >= 0.75 { self.messenger .send("Warning: You've used up over 75% of your quota!"); } } }
implMessengerforMockMessenger { fnsend(&self, message: &str) { self.sent_messages.push(String::from(message)); // not allowed. cannot borrow `self.sent_messages` as mutable, as it is behind a `&` reference } }
We can’t modify the MockMessenger to keep track of the messages, because the send method takes an immutable reference to self. We also can’t take the suggestion from the error text to use &mut self instead, because then the signature of send wouldn’t match the signature in the Messenger trait definition
This is a situation in which interior mutability can help!
if percentage_of_max >= 1.0 { self.messenger.send("Error: You are over your quota!"); } elseif percentage_of_max >= 0.9 { self.messenger .send("Urgent warning: You've used up over 90% of your quota!"); } elseif percentage_of_max >= 0.75 { self.messenger .send("Warning: You've used up over 75% of your quota!"); } } }
#[cfg(test)] mod tests { use super::*; use std::cell::RefCell;
implMessengerforMockMessenger { fnsend(&self, message: &str) { self.sent_messages.borrow_mut().push(String::from(message)); // call borrow_mut on the RefCell<Vec<String>> in self.sent_messages to get a mutable reference to the value inside the RefCell<Vec<String>> } }
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1); // call borrow on the RefCell<Vec<String>> to get an immutable reference to the vector. } }
Keeping Track of Borrows at Runtime with RefCell
When creating immutable and mutable references, we use the & and &mut syntax, respectively. With RefCell, we use the borrow and borrow_mut methods, which are part of the safe API that belongs to RefCell. The borrow method returns the smart pointer type Ref, and borrow_mut returns the smart pointer type RefMut. Both types implement Deref, so we can treat them like regular references.
The RefCell keeps track of how many Ref and RefMut smart pointers are currently active.RefCell lets us have many immutable borrows or one mutable borrow at any point in time. If we try to violate these rules, rather than getting a compiler error as we would with references, the implementation of RefCell will panic at runtime.
When we run the tests for our library, the code in will compile without any errors, but the test will fail thread ‘main’ panicked at ‘already borrowed
Having Multiple Owners of Mutable Data by Combining Rc and RefCell
A common way to use RefCell is in combination with Rc. If you have an Rc that holds a RefCell, you can get a value that can have multiple owners and that you can mutate!
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc;
fnmain() { letvalue = Rc::new(RefCell::new(5)); // We create a value that is an instance of Rc<RefCell<i32>> and store it in a variable named value so we can access it directly later.
leta = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil))); // Then we create a List in a with a Cons variant that holds value. We need to clone value so both a and value have ownership of the inner 5 value rather than transferring ownership from value to a or having a borrow from value. We wrap the list a in an Rc<T> so when we create lists b and c, they can both refer to a
*value.borrow_mut() += 10; // After we’ve created the lists in a, b, and c, we add 10 to the value in value. We do this by calling borrow_mut on value, which uses the automatic dereferencing feature to dereference the Rc<T> to the inner RefCell<T> value. The borrow_mut method returns a RefMut<T> smart pointer, and we use the dereference operator on it and change the inner value.
println!("a after = {:?}", a); println!("b after = {:?}", b); println!("c after = {:?}", c); }
The standard library has other types that provide interior mutability, such as Cell, which is similar except that instead of giving references to the inner value, the value is copied in and out of the Cell. There’s also Mutex, which offers interior mutability that’s safe to use across threads;
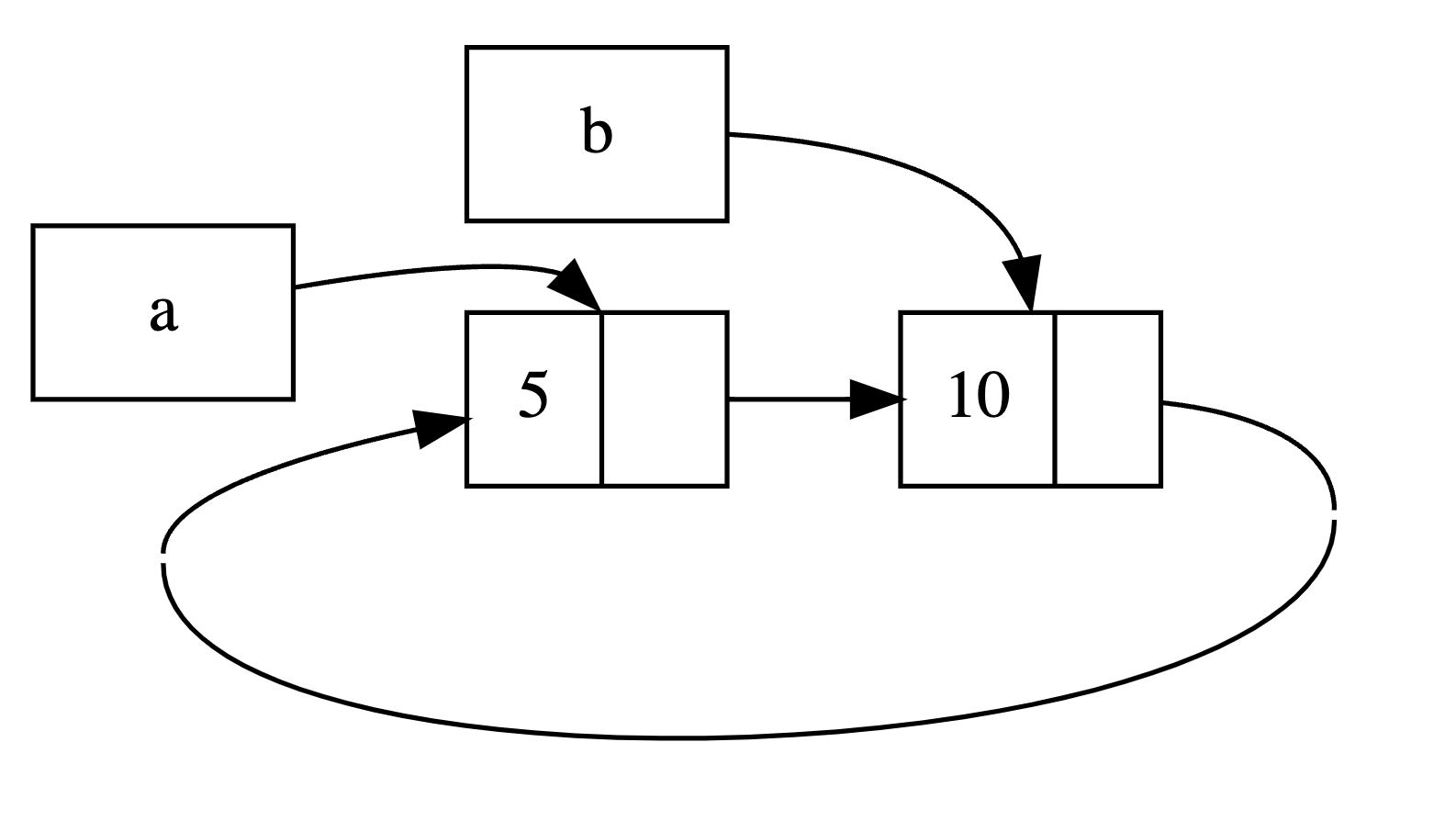
Reference Cycles Can Leak Memory
Rust’s memory safety guarantees make it difficult, but not impossible, to accidentally create memory that is never cleaned up (known as a memory leak).
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc;
#[derive(Debug)] enumList { Cons(i32, RefCell<Rc<List>>), // The second element in the Cons variant is now RefCell<Rc<List>>, meaning that we want to modify which List value a Cons variant is pointing to. Nil, }
implList { fntail(&self) ->Option<&RefCell<Rc<List>>> { // We’re also adding a tail method to make it convenient for us to access the second item if we have a Cons variant. matchself { Cons(_, item) => Some(item), Nil => None, } } }
fnmain() { use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc;
letb = Rc::new(Cons(10, RefCell::new(Rc::clone(&a)))); // his code creates a list in a and a list in b that points to the list in a
println!("a rc count after b creation = {}", Rc::strong_count(&a)); println!("b initial rc count = {}", Rc::strong_count(&b)); println!("b next item = {:?}", b.tail());
ifletSome(link) = a.tail() { *link.borrow_mut() = Rc::clone(&b); // modifies the list in a to point to b, creating a reference cycle }
println!("b rc count after changing a = {}", Rc::strong_count(&b)); println!("a rc count after changing a = {}", Rc::strong_count(&a));
// Uncomment the next line to see that we have a cycle; // it will overflow the stack // println!("a next item = {:?}", a.tail()); } // At the end of main, Rust drops the variable b, which decreases the reference count of the Rc<List> instance from 2 to 1. The memory that Rc<List> has on the heap won’t be dropped at this point, because its reference count is 1, not 0. Then Rust drops a, which decreases the reference count of the a Rc<List> instance from 2 to 1 as well. This instance’s memory can’t be dropped either, because the other Rc<List> instance still refers to it. The memory allocated to the list will remain uncollected forever.
Preventing Reference Cycles: Turning an Rc into a Weak
So far, we’ve demonstrated that calling Rc::clone increases the strong_count of an Rc instance, and an Rc instance is only cleaned up if its strong_count is 0. You can also create a weak reference to the value within an Rc instance by calling Rc::downgrade and passing a reference to the Rc. When you call Rc::downgrade, you get a smart pointer of type Weak. Instead of increasing the strong_count in the Rc instance by 1, calling Rc::downgrade increases the weak_count by 1. The Rc type uses weak_count to keep track of how many Weak references exist, similar to strong_count. The difference is the weak_count doesn’t need to be 0 for the Rc instance to be cleaned up.
Strong references are how you can share ownership of an Rc instance. Weak references don’t express an ownership relationship. They won’t cause a reference cycle because any cycle involving some weak references will be broken once the strong reference count of values involved is 0.
Because the value that Weak references might have been dropped, to do anything with the value that a Weak is pointing to, you must make sure the value still exists. Do this by calling the upgrade method on a Weak instance, which will return an Option<Rc>. You’ll get a result of Some if the Rc value has not been dropped yet and a result of None if the Rc value has been dropped.
Creating a Tree Data Structure: a Node with Child Nodes
#[derive(Debug)] structNode { value: i32, parent: RefCell<Weak<Node>>, // To make the child node aware of its parent, we need to add a parent field to our Node struct definition. The trouble is in deciding what the type of parent should be. We know it can’t contain an Rc<T>, because that would create a reference cycle with leaf.parent pointing to branch and branch.children pointing to leaf, which would cause their strong_count values to never be 0. children: RefCell<Vec<Rc<Node>>>, }
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); // try to get a reference to the parent of leaf by using the upgrade method, we get a None value.
letbranch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), // We clone the Rc<Node> in leaf and store that in branch, meaning the Node in leaf now has two owners: leaf and branch. });
*leaf.parent.borrow_mut() = Rc::downgrade(&branch); // use the Rc::downgrade function to create a Weak<Node> reference to branch from the Rc<Node> in branch.
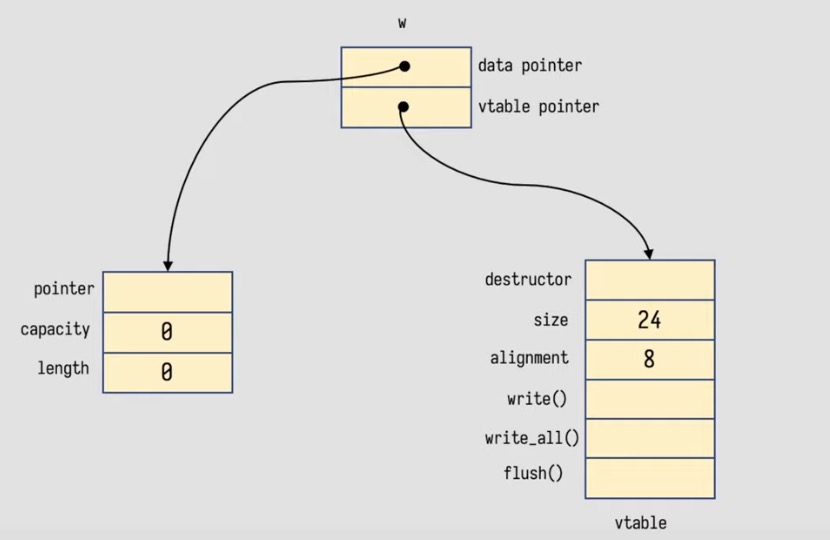
in both ways, buffer is converted to a trait object implements Write
in memory, a trait object (in the example, w) is a fat point consists two pointers the vtable is generated once at compile time and shared by all objects of the same type. the vtable contains pointers to the machine code of the functions that must be present for a type to be a “Writer”