Introduction
Kademlia, a peer-to-peer distributed hash table(DHT). Some other DHT techniques are Chord. In the Kad network, each node has a unique 160-bit ID (ETH account address is 20 bytes, which is 160 bits) <key,value> pairs are stored in nodes whose ID is ‘close’ to the key for some notion of closeness.
system description
Kad effectively treats nodes as leaves in a binary tree, with each nodes’s position determined by the shortest unique prefix of its ID. Figure 1 shows the position of a node with unique prefix 0011 in an example.
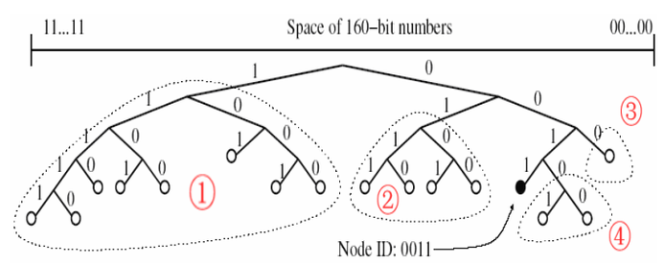
for any given node, the binary tree is divided into a series of successively lower subtrees that don’t contain the node.
The highest-level subtree is composed of the other half of the whole tree that does not contain itself; the next level of subtree is composed of the remaining half that does not contain itself; and so on, until the complete tree is split into n subtrees. As shown in the figure, the part contained by the dotted line is the subtree of node 0011.
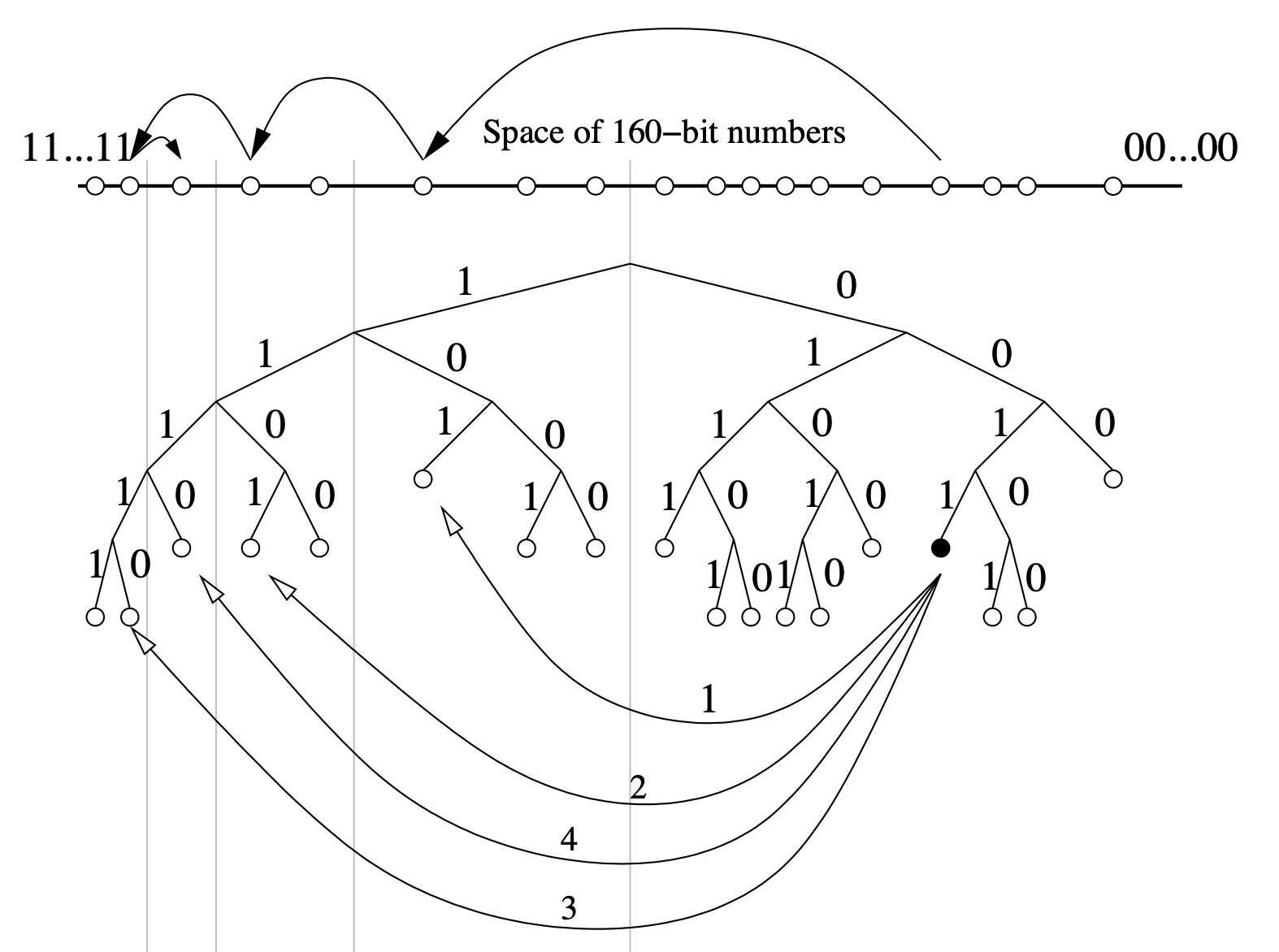
if there is at least one node knwon in each subtree (in total, at least n nodes), a recursive routing algorithm can be used to reach any node within the binary tree. Figure 2 shows an example of node 0011 locating node 1110 by successively querying the best node it knows of to find contacts in lower and lower subtrees; finaly the lookup converges to the target node.
node distance: XOR metric
Node’s id is 160 bit. Keys are also 160 bit. The Kad algorithm uses an XOR operation to calculate the distance between nodes.
d(x,y) = x XOR y
node state
for each 0 <= i < 160, every node keeps k <IP address, UDP port, node ID> triples (as a list) for nodes of distance between 2^i and 2^i+1 from itself. it is called k-buckets.
each k-bucket is kept sorted by time last seen–least recently seen node at the head, most-recently seen at the tail.
for small values of i, the k-buckets will generally be empty (as no approriate nodes will exist).
The K value mentioned here is a system-level constant (must be an even number). It is set by the software system using Kad (for example, the Kad network used by BT download, K is set to 8).
update of k bucket
There are mainly the following ways to update the K bucket:
- Actively collect nodes: Any node can initiate a FIND_NODE (query node) request to refresh the node information in the K-bucket.
- Passive collection node: When receiving requests from other nodes (such as: FIND_NODE, FIND_VALUE), it will add the node ID of the other party to a certain K-bucket.
- Detect invalid nodes: By initiating a PING request, determine whether a node in the K-bucket is online, and then clean up which offline nodes in the K-bucket.
The update principle is to insert the latest node into the tail of the queue, and not to remove the online nodes in the queue.
According to the K-bucket update principle, nodes with a long online time are more likely to remain in the K-bucket list. Therefore, by keeping the nodes with a long online time in the K-bucket, Kad will significantly increase the number of nodes in the K-bucket. it can defend against DOS attacks to a certain extent, because only when the old node fails, Kad will update the K bucket information, which avoids flooding routing information through the addition of new nodes
RPC method
The Kademlia protocol includes four remote RPC operations: PING, STORE, FIND_NODE, FIND_VALUE.
- PING probes a node to see if it is online.
- STORE instructs a node to store a <key,value> pair for later retrieval.
- FIND_NODE takes a 160bit ID as an argument. The receiver of this operation returns the (IP address, UDP port, Node ID) information of K nodes that it knows are closer to the target ID. The information of these nodes can be obtained from a single K-bucket, or from multiple K-buckets. In either case, the receiver will return the information of K nodes to the operation initiator.
- The FIND_VALUE operation is similar to the FIND_NODE operation, with one exception. if the RPC receipients has received a STORE RPC for the key, it just returns the stored value.
node lookup
Kad participant must locate the k closest nodes to some given node ID. Kad employs a recursive algorithm for node lookups. It recursively send FIND_NODE requests to \alpha (out of k) closest nodes it knows of.
find a <key,value> pair
to find a <key,value> pair, a node starts by performing a lookup to find the k nodes with IDs closest to the key. However, value lookups use FIND_VLAUE rather than FIND_NODE RPCs.
node join
to join the network, a node u must have a contact to an already participating node w.